


미션 도중 생긴 고민 💭
public Cars(List<String> carNames) {
ArrayList<Car> cars = new ArrayList<>();
for (String carName : carNames) {
cars.add(new Car(carName));
}
this.cars = cars;
}
Cars 객체를 생성할 때, List<String>형태의 carNames를 입력받은 뒤,For-Loop 문을 통해 cars 필드를 초기화 해주었다.
하지만 For-Loop문을 생성자 로직에 적용하니 개인적으로 생성자 로직이 지저분하다는 생각이 들었다.
때문에 Stream을 사용하여 짧고 가독성있는 코드로 리팩토링하여 사용하고자 하였다.
그리고 이때 머릿속에 한가지 고민이 생겼다 🤔
미션의 요구사항에 자동차의 수는 제한이 없는데,
그럼 Integer.MAX_VALUE 대의 자동차 이름을 입력받았을 때 For-Loop와 Stream 중
무엇이 더 성능 면에서 뛰어날까?
성능이 더 좋은 것을 사용해야 할텐데,,
고민 해소을 위한 웹서칭 결과
평소 자세한 이유는 몰랐지만 주워들은 것이 있어 Stream의 성능이 더 좋지 않을 것이라고 생각했는데,
정말 Stream을 사용하는 것이 For-Loop를 사용하는 것보다 성능이 안 좋다고 한다.
💡 가장 큰 이유는 For-Loop는 만들어진지 40년 이상 지났기 때문에 최적화가 굉장히 잘 되어 있었고,
Stream은 2015년 쯤에 Java8과 함께 생겨났기 때문에 아직 최적화 작업이 덜 되어있다는 것이 원인이라고 하는데,,
여기서 또 하나의 고민이 생겼다 🤔
💭 그럼 무조건 For-Loop만을 사용해야만 하는 걸까?
나는 이 고민을 해소하기 위해 Stream과 For-Loop의 차이에 대해 공부를 시작하게 하게 되었고,
그 과정에서 좋은 글을 발견하여 학습하며 알게된 것을 공유하고자 포스팅을 작성하게 되었다.
Stream과 For-Loop의 성능 비교 🏁
Primitive Type 성능 비교 📝
Primitive Type의 경우 JVM 메모리의 Stack에 값을 저장하고 있기 때문에
접근 속도가 빨라 For-Loop가 본래의 성능을 발휘할 수 있기에 빠른 반복문 수행이 가능하다.
스택(Stack)이란? 🤔
JVM의 스택(Stack)은 실행중인 스레드의 함수 호출 및 지역 변수 관리에 사용되며,
각 스레드는 자체 스택을 가진다.
Primitive Type은 변수 선언 시 JVM의 Stack 에 값을 저장하고, 변수 호출 시에 Stack에서 값을 바로 불러오는 방식을 채택하기 때문에 접근 속도가 굉장히 빠르다.
예를 들어, Primitive Type인 int 타입의 변수에 42라는 값을 저장하는 경우 42가 스택에 저장되며,Stack에 저장된 값은 변수가 선언된 스코프(블록) 내에서만 사용 가능하다.
때문에 Primitive Type의 경우 Stream을 사용했을 때와, For-Loop를 사용했을 때
일반적으로 예측 가능한 결과를 내놓는다.
Test 로직 🧪
public class StreamAndForLoop {
static final int MAX_INT = 5000000;
static int[] testData = new int[MAX_INT];
public static void main(String[] args) {
init();
calcForLoop();
calcStream();
}
private static void init() {
for (int i = 0; i < MAX_INT; i++) {
testData[i] = i;
}
}
private static void calcStream() {
int standard = 0;
long before = System.currentTimeMillis();
Arrays.stream(testData)
.filter(t -> t > standard)
.count();
System.out.println("Stream : " + (System.currentTimeMillis() - before));
}
private static void calcForLoop() {
int standard = 0;
int count = 0;
long before = System.currentTimeMillis();
for (int data : testData) {
if(data > standard) {
count++;
}
}
System.out.println("For-Loop : " + (System.currentTimeMillis() - before));
}
}
이는 standard라는 변수에 저장된 값과, testData에 저장된 값들의 크기를 비교하여
더 큰 값이 존재하면 count하는 로직을 Stream과 For-Loop 방식으로 각각 5000000번 수행하는 코드이다.
로직 수행 결과 📈
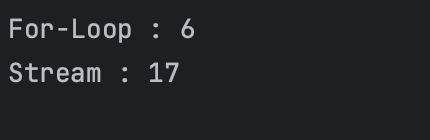
당연하게도 Primitive Type은 접근 속도가 빠르기 때문에 일반적인 경우인
“For-Loop 방식이 더 빠르다” 라는 말에 들어맞는 결과가 출력된다.
결론적으로,
실험한 5000000번의 경우에는 3배 가까이 차이가 나는 것을 확인할 수 있다.
Wrapped Type 성능 비교 📝
그렇다면 Wrapped Type은 어떨까?
Wrapped Type의 경우 Primitive Type과 달리 값을 저장할 때, Heap 메모리에 저장한다는 특징이 있다.
힙 메모리(Heap Memory)란? 🤔
Wrapped Type 변수가 선언되면 Heap 메모리에 객체가 할당되고, Stack에는 객체를 담고 있는 Heap 메모리 주소가 저장된다.
결국 우리는 Stack에 저장된 Heap 메모리 주소를 참조하여 Heap메모리에 접근하는 방식을 사용함으로써 저장된 데이터에 접근할 수 있게 되는 것이다.
말로만 들어도 Stack에 값을 저장하고 바로 참조할 수 있는 Primitive Type의 접근 방식보다 느려보이는데,
과연 위에서 사용했던 로직과 같은 로직을 Wrapped Type 으로 변환하여 실행시키면 어떤 결과가 나올까?
Test 로직 🧪
public class StreamAndForLoop {
static final int MAX_INT = 5000000;
static List<Integer> testData = new ArrayList<>();
public static void main(String[] args) {
init();
calcForLoop();
calcStream();
}
private static void calcStream() {
int standard = 0;
long before = System.currentTimeMillis();
testData.stream()
.filter(t -> t > standard)
.count();
System.out.println("Stream : " + (System.currentTimeMillis() - before));
}
private static void calcForLoop() {
int standard = 0;
int count = 0;
long before = System.currentTimeMillis();
for (Integer data : testData) {
if(data > standard) {
count++;
}
}
System.out.println("For-Loop : " + (System.currentTimeMillis() - before));
}
private static void init() {
for (int i = 0; i < MAX_INT; i++) {
testData.add(i);
}
}
}
이는 위와 똑같이 standard라는 변수에 저장된 값과 testData에 저장된 값들의 크기를 비교하여
더 큰 값이 존재하면 count하는 로직을 수행한다.
하지만 이전처럼 Primitive Type을 사용하지 않고 Wrapped Type인 Integer를 사용하도록 변경하였다.
과연 Wrapped Type을 사용했을 때, 결과는 어떨까?
로직 수행 결과 📈

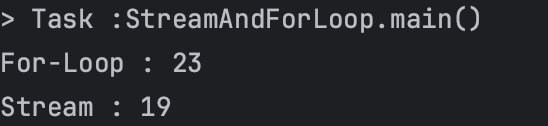
신기하지 않은가?? 아까는 3배 가까이 차이가 나던 실행 결과가 이제는 거의 동일한 수준으로 측정되거나 역전해버렸다.
이는 Stack에 저장된 데이터(객체)의 주소를 통해 Heap 메모리에 접근하여 참조하는 비용이Stack에 값을 저장하고 호출 시에 바로 값에 접근하는 비용에 비해 굉장히 크기 때문에,Stream과 For-Loop의 속도 격차를 완화시켜버린 것이다.
💡 이를 통해 Wrapped Type을 사용하는 For-Loop 경우,
Stream을 사용하는 경우와 비용이 크게 차이나지 않으므로,
가독성이 더 좋은 측을 선택하여 개발해도 괜찮다는 인사이트를 얻을 수 있었다.
로직 변경 ♻️
변경 전
public Cars(List<String> carNames) {
ArrayList<Car> cars = new ArrayList<>();
for (String carName : carNames) {
cars.add(new Car(carName));
}
this.cars = cars;
}
내가 고민하던 로직의 경우 String이라는 Wrapped Type을 사용하고 있었기에,
관리하던 생성자 로직에 Stream을 적용하여 아래와 같이 변경하였다.
변경 후
public Cars(List<String> carNames) {
this.cars = carNames.stream()
.map(Car::new)
.toList();
}ArrayList<Car>객체 선언 후, 반복문을 돌며 객체에 값을 저장하지 않아도 되기 때문에ArrayList<Car> cars변수 선언부 삭제 후, 필드에 바로 초기화하도록 수정Stream을 사용하여 짧고 간결한 코드 작성으로 가독성 향상- 굉장히 많은 반복 작업을 거친다고 해도
For-Loop문과 비교하여더 좋거나 비슷한 성능을 발휘함
'Language > Java' 카테고리의 다른 글
| [Java] Javac의 동작 과정은 어떻게 될까? (3) | 2024.11.21 |
|---|---|
| [Java] Fluent API란? (feat. JDBC에 적용해보기) (0) | 2024.04.04 |
| [Java] 생성자 체이닝(Constructor Chaining) 기법 (0) | 2024.04.02 |
| [Java] 자바에서 라인을 ‘안전하게’ 개행하는 방법 (2) | 2024.03.01 |
| [Java] 클래스 멤버는 각자의 위치가 존재한다 (0) | 2024.02.28 |